Text to XML Configuration
This is a module for InterFormNG, so you cannot use it, unless you have a license code which opens up for this functionality. This module makes it possible to convert text and similar e.g. csv files into xml files, which can be handled by InterFormNG.
The module has these configuration parameters:
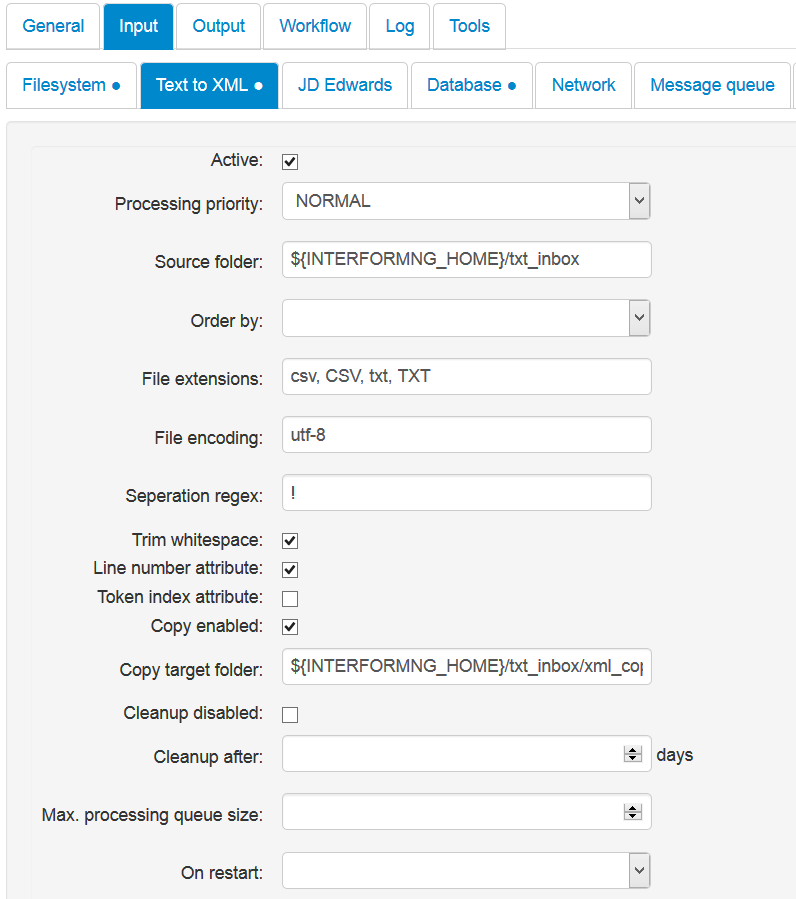
The parameters specific for this module are:
Processing priority
Batch, Normal and immediate. Batch has the lowest priority.
Source Folder
The path to the folder(s), which is scanned for new text files. If you want to monitor multiple folders, you need to separate them with a comma (,).
Order by
With this you select the sequence in which the input XML files are to be processed. Possible values are:
Don't care |
The sequence is irrelevant. |
Filename |
The input files are processed in alphanumeric order. |
Timestamp |
Oldest XML files are processed first. |
File extensions
The extension of the files, that you want to convert into XML. The possible extensions must be delimited with a comma. This is case sensitive.
File encoding
The expected encoding of the incoming text files. The supported encoding depends on which java version you run. The supported list with Java 1.8 can be found here: http://docs.oracle.com/javase/8/docs/technotes/guides/intl/encoding.doc.html
In InterformNG you refer to the encoding in the left most or the second left most column. InterFormNG is case insensitive as to how you write the file encoding.
Separation Regex
This is a REGEX (regular expression) for the delimiter which defines the next element on each line in the text file. Independently of this a Carriage Return <CR> or Line Feed <LF> or a combination of both will result in a new line node in the output XML file. Each element separated by the delimiter will be inserted as a separate node in the XML file. For a comma separated file this should be a comma.
You can e.g. state a list of delimiter characters in these brackets: []. More details of regular expressions can be found here:
https://en.wikipedia.org/wiki/Regular_expression
Trim Whitespace
If yes, any leading or trailing spaces after/before the delimiter will be removed before copying the file to XML.
Line number attribute
If activated, an attribute like line='1', line=’2' etc. will be added to each line node in the output xml file.
Token index attribute
If there are multiple elements per line separated by the separation regex mentioned above, then it makes sence to active this option. This will add an attribute like idx=’1', id=’2' etc. to each element on each line - and start from 1 on each new line. This makes it possible to select a specific ‘column’ on a line in an easy way.
Copy enabled
The resulting xml files are normally directly used for processing e.g. in the workflow without adding the files as real, accessible files. If you want that e.g. to verify the result and e.g. to use them to create a fitting template, then you should activate the copying via this option. The path used is set in the option below.
Copy target folder
The folder where the XML result should be created. This is activated via the Copy enabled option above.
Cleanup disabled
As default processed, old input Text files are deleted, but if you activate this i.e. disable cleanup, then old, processed input files are not deleted.
Cleanup after
How old (how many days) the processed input text files should be, before they are deleted.
Max. Processing queue size
The number of input text files, that will be moved into the processing folder (for further processing) at a time. If many input files are arriving within a short interval - or if you are starting up processing on a folder with many files, then a max. size should be stated.
On restart
What to do, if the document processor starts and detects old (half processed) files in the processing subfolder. Possible values are:
Rename processing subfolder
The current processing folder is renamed, and the new name includes the current data. That means, that the files, that where processed while the server ended the last time are NOT rerun, and you need manually to copy the files back into the input folder, if you want to process them from scratch.
Move unprocessed files back
The files found in the processing folder are moved back into the input folder, so they are rerun again from scratch. That means, that some output might be generated twice.