This workflow input type is very similar to the input type, From IBM i output queue except that you can monitor multiple output queues with this workflow input type contrary to From IBM i output queue.
For the most of the parameters you should refer to the similar input type, From IBM i output queue and below the focus is on the additional parameters and the difference between the two input types.
The input type, From IBM i output queue (multiple) has these special parameters:
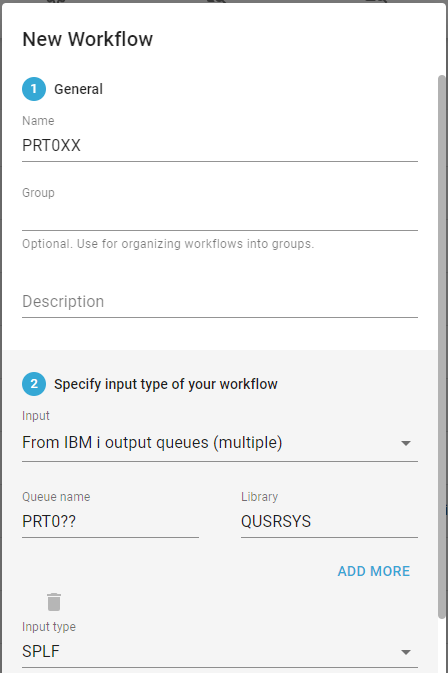
Queue name
Here you can state a generic name of the output queue, where you can use the special characters * and ?. The '*' indicates any string of any length and '?' indicates a single, generic character.
With the value PRT0?? as above InterFormNG2 will monitor the output queues named in the range PRT000 to PRT099 and it will create and attach a data queue to each of these monitored output queues. With this setup output queues named e.g. PRT000I or PRT000O are not monitored. If e.g. the specification was PRT0*, then any output queue starting with these characters are monitored by InterFormNG2. It is highly recommended to restrict this name as much as possible to ensure that you are not monitoring more output queues than intended. You should also notice the remark below concerning the use of memory and the sequence.
Library
The library in which the output queues are stored.
You can add more lines to the output queue selection with the Add more icon.
Important notice
The multiple output queue monitor process the spooled files in a different manner than the monitor for single output queues. The differences are listed below:
The sequence
This workflow component is in the background initiating a new workflow instance for each spooled file, that is processed. If many spooled files are generated in a short time, the many spooled files will be processed simultaneously, so you cannot be sure that the outputs of the many spoooled files are processed in the same sequence as they where generated. If you want to ensure, that the generated output is produced in the same sequence as they where generated, then you might need to save the spoooled files first and then ensure that they are processed one by one.
Memory usage
As the spooled files are processed in parallel the use of memory will be higher than when just processing a single spooled file at a time. To limit the use of memory you can consider to handle small spooled files differently than larger spooled files. Often the required response time also depends on the spooled file size or type. Her you can consider to process larger spooled files slower (with less memory usage) or even delay processing of these larger files.