The processing of spooled files on an output queue is single threaded, so if you are processing larger spooled files (that takes longer to process and print), then smaller spooled files on the same output queue might wait for the processing of a larger spooled file to be done. To avoid such a bottleneck you can consider a setup where the spooled files can be processed in parallel.
This can be done in a couple of ways:
1.Move larger spooled files to another output queue to avoid them blocking the smaller ones. This setup is the easiest one to setup and understand.
2.Save larger spooled files as .splf files and e.g. save them to a monitored folder where another workflow is to monitor and process these files. This setup is more complicated and has some limitations, but on the other hand it can be setup to be real multi-thread.
Move larger spooled files to another output queue
One way to avoid that larger spooled files (that takes longer to process and print) are blocking smaller spooled files is to consider to move the larger spooled files to another output queue, so that they can be processed on the other output queue while the current output queue processor continues with other smaller spooled files.
Here is how that can be implemented:

Each element is covered below:
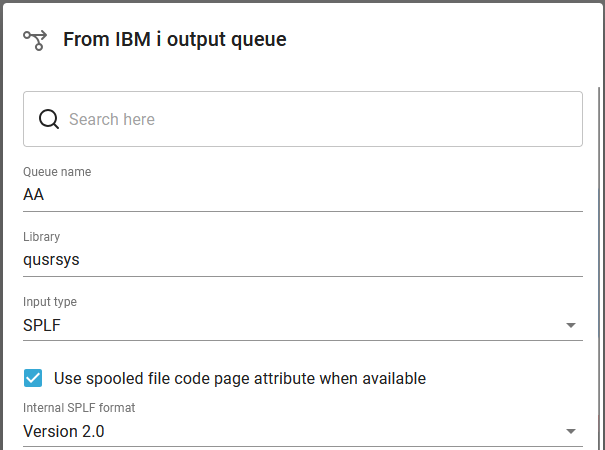
1. Read from IBM i output queue.
With this workflow input type we read in this case spooled files from the output queue, QUSRSYS/AA:
2. Choice component:
With the Choice component we can decide which branch to execute depending on a condition. In this case the condition is setup as below:
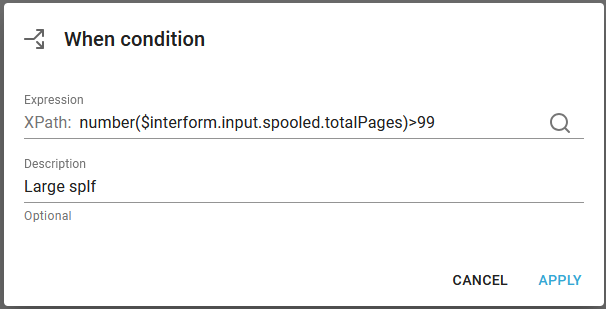
Here we compare the total number of pages of the input spooled file with a threshold value to decide if a spooled file is large or not. We use the number() function to convert the string, that contains the total number of pages into a number, which means that we can do a normal numeric comparison. If we forget the number() function, then we will see this error message in the workflow, when we later run it:
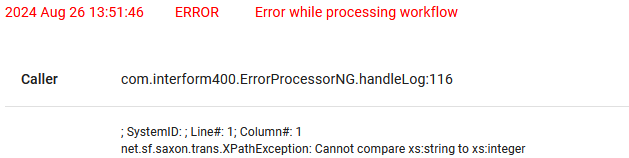
The error message "Cannot compare xs:string to xs:integer" refers to a comparison between the variable interform.input.spooled.totalPages (which is a string) with the number 99 (which is an integer - or number).
With the condition above the when branch will be executed if the input spooled file contains 100 pages or more.
3. Post-process spooled file (Move)
In the when branch we insert a Post-process spooled file component in order to move the (large) spooled file to another output queue, if it is large. The move is specified like below:
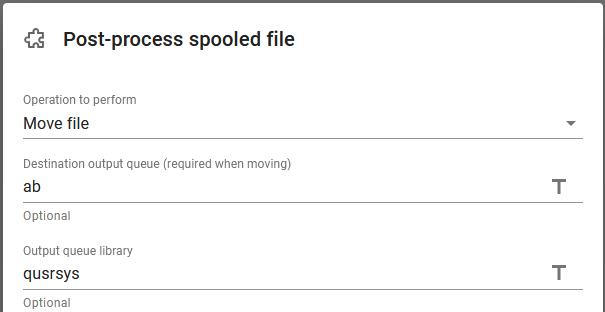
So if the spooled file is considered large, then we choose to move it to the output queue, QUSRSUS/AB for processing and immediately the next spooled file is processed.
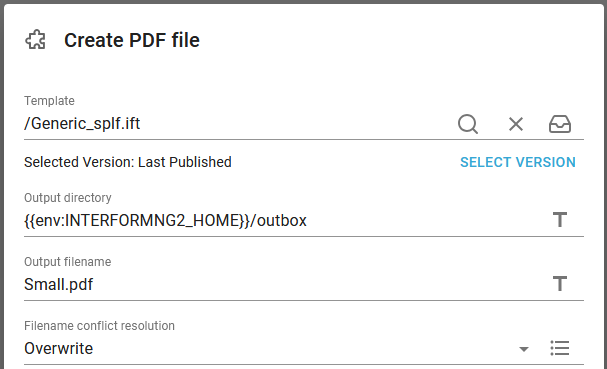
Inside the otherwise branch of the choice component we can setup the processing of the normal spooled files. In this case we have chosen to create a PDF file based on this spooled file like below:
5. Post-process spooled file (Hold)
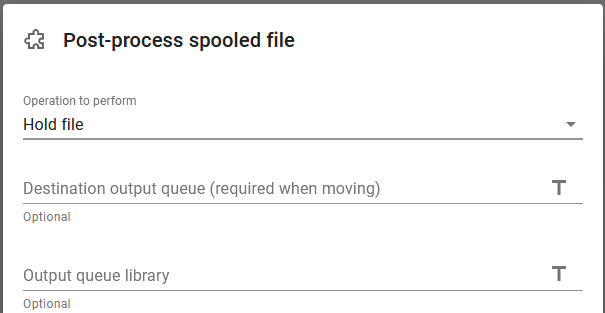
The last workflow component is a Post-process spooled file one, which is to hold the normal input spooled file like below:
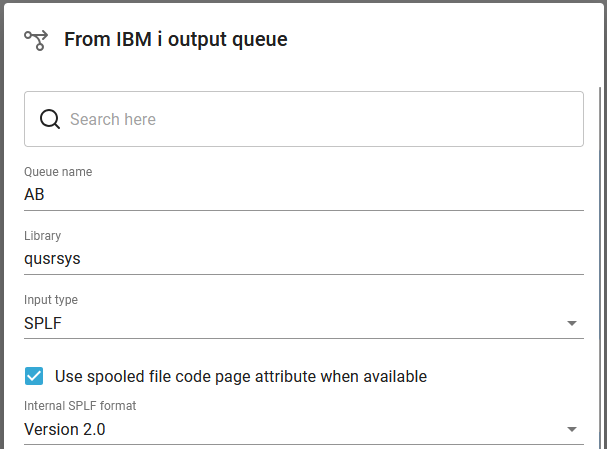
The only thing missing is the setup on the other output queue, QUSRSYS/AB, which is to handle the large spooled files. This case this is setup like below:

The 3 components are here setup like below:
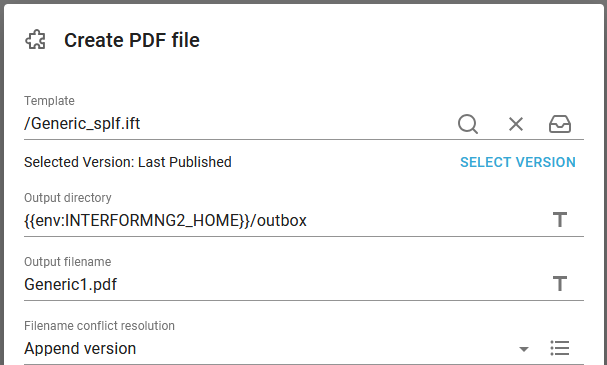
2) Create PDF file:
3) Post-process spooled file (Hold):
If you intend to run the same sub-workflow components in both workflows, then you can consider to build a common sub-workflow and call that from both main workflows.
Save larger spooled files as .splf files and process them in another workflow
The setup above is normally to be recommended, but there is an alternative if you have many, larger spooled files and you e.g. either do not want the extra output queue or want a real multi-thread alternative. Most of the setup is the same as in the example above and only the differences are covered below. Here the main workflow looks like below:

The differences are seen in the branch for the large spooled files:
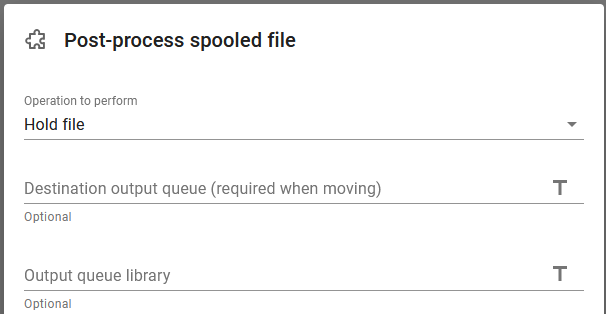
1) Post-process spooled file (Hold)
Here we need to hold the spooled file first (and/or change other spooled file attributes) as the new, target workflow is unable to change the original input spooled file. Here it is simply being held:
Here we save the input spooled file into a .splf file in a folder, that is monitored by another workflow. The save is defined like below:
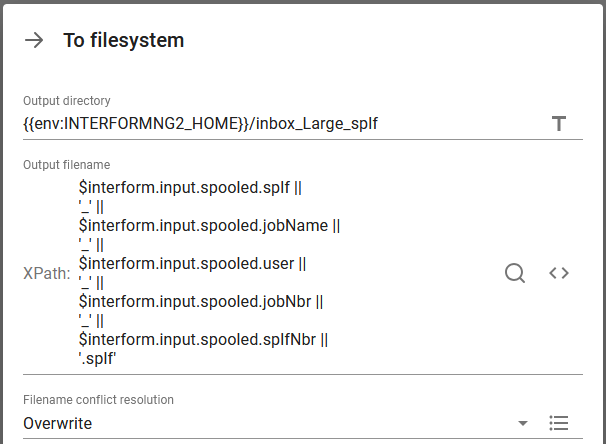
The full expression is this:
$interform.input.spooled.splf || '_' || $interform.input.spooled.jobName || '_' || $interform.input.spooled.user || '_' || $interform.input.spooled.jobNbr || '_' || $interform.input.spooled.splfNbr || '.splf'
The function || is a concat function, so this expression extracts these attributes from the input spooled file and they are concatenated with an underscore between each - and the file is saved with the extension, .splf.
The attributes/variables are covered here in the manual.
Here the spooled file identification is saved as the spooled file name, job name, user profile, job number, spooled file number, but in principle we should also consider to include the timestamp.
The large spooled files are then to be handled in another workflow, that monitors the same folder into which the .splf files are saved. This is here done as below:
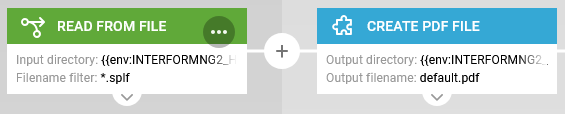
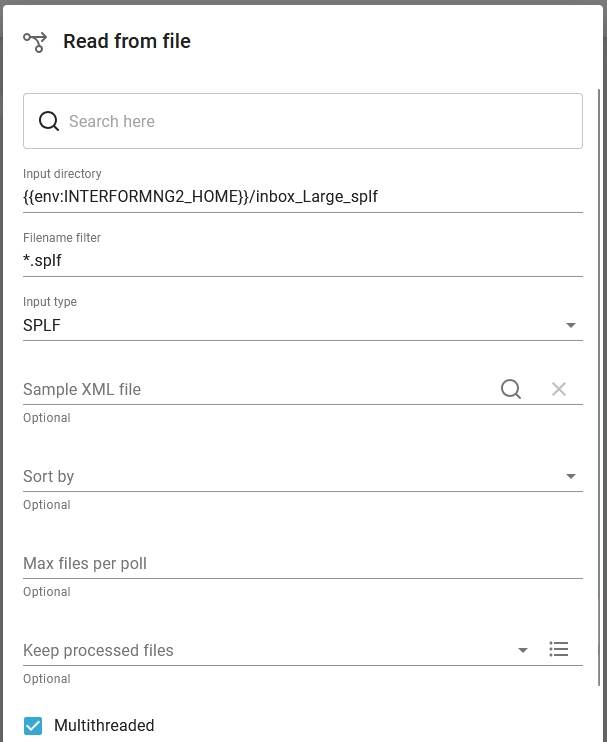
1) Read from file.
Here we monitor the folder, that is saved to above:
Please notice, that we here can activate the Multithreaded option to ensure, that also the larger spooled files are processed as fast as possible.
2) Create PDF file.
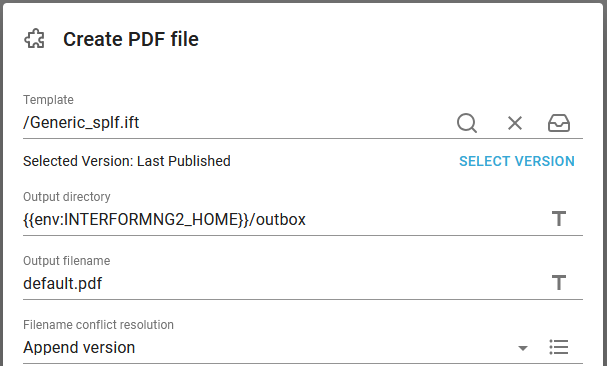
We here choose to create a PDF file from the .splf file:
Limitation of the last solution
For this last solution you should notice the limitations:
1) The status and attributes of the large input spooled file cannot be set to reflect the result of the processing, where the first solution is able to reflect that: In solution 1 the spooled file is only held after it has succesfully been processed.
2) In the second solution the second workflow (that monitors the folder) is unable to use the predefined workflow variables for the spooled file, but it can however find the same information as spooled file attributes.