In InterFormNG2 you use the language XPath for referencing to data from the XML file. There are many sources of information, if you want to know more about XPath, but you can also simply read the few examples below to have a good idea of how it can be used with InterFormNG2. Help for entering XPath functions can be found in the XPath wizard.
This section includes these XPath examples:
Apart from the general XPath functions linked below there is also a long list of special InterFormNG2 built in XPath functions.
1.Refer to a simple node in input XML file (XML reference).
2.Iterate across multiple detail lines (repeat).
3.Do a repeat loop for a subset of nodes (with a special attribute, a special node name or value in the subtree).
4.Concatenate (add) multiple strings together (concat).
5.Select a part of a string with a start position and length (substring).
6.Search a string and select only the part left to where the search string is found (substring-before).
7.Search a string and select only the part to the right of where the search string is found (substring-after).
8.Search a string to determine if another string is found in that or not (contains).
9.Replace all occurrences of string1 in a main string with the new string2 (replace).
10.Replace or remove all occurrences of specific characters in a string (translate).
11.Print of the current date/time (current-date()).
12.Add or subtract a number of days, months or years to/from a date.
14.Condition an element on the current date.
15.Numeric operations (+-*/).
16.Rounding off numbers (round(), floor() and ceiling()).
17.Format numbers.
18.XML reference via node number.
19.XML reference via a condition on a value.
20.Boolean expressions/comparisions (notice the not equal note) and if..then..else.
22.Variables in Xpath
23.How to calculate the sum of nodes.
24.How to calculate the number of specific nodes and e.g. verify if a node exists.
25.How to use attributes of a node.
26.How to ignore namespaces in XPath expressions.
27.How to group nodes and e.g. summarize values from the grouped nodes.
28.List values of all nodes, with a generic node name (starting with xxx).
29.Refer to a node via the index number.
30.Select a range of nodes via the index/position().
32.Test if a node is not blank.
34.A good way to compare data is with the ng:compare function.
35.Introduction to the boolean() function.
36.How to add preceding/leading or trailing zeroes/blanks to a string.
37.Avoid warnings in the job logs for repeats, that selects no nodes.
38.Identify the current line number within a repeat e.g. in a transformation.
39.Tokenize: Convert a string into a list and use index for references to this list
40.Solution for error: Unsuitable types for + operation (xs:string, xs:integer) in the workflow
41.Connect preceding or following node sets to the main node set
Simple reference to a node in input XML file
In XPath you can e.g. refer to data in this XML file:
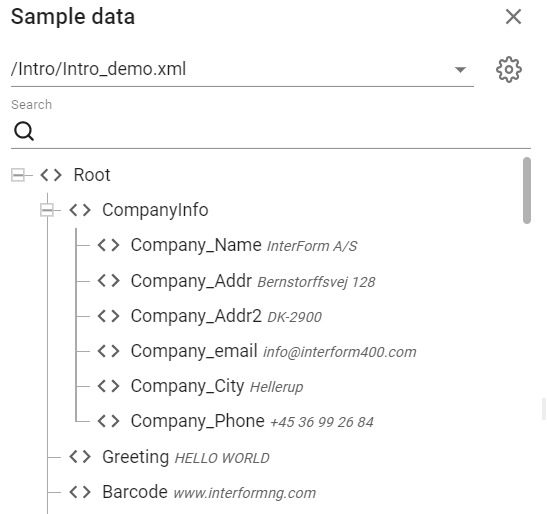
If you type this in InterFormNG2 as the XPath:
/Root/Greeting
Then you will get the value of this node, which here equals "HELLO WORLD".
Please note that the Xpath is case sensitive, and xpath functions are written in lower case!
Starting with a ‘/’ indicates that you are referring to the node from the root of the XML file.
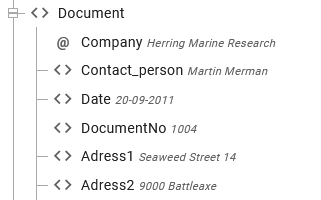
If you insert this Repeat Element, then InterFormNG2 will run the elements inside of the Repeat loop for each Document node in the XML file:
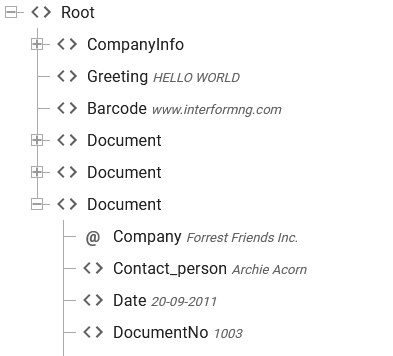

You can then inside of the Repeat loop refer to the DocumentNo inside each Document node with an Xpath like this in a text element:
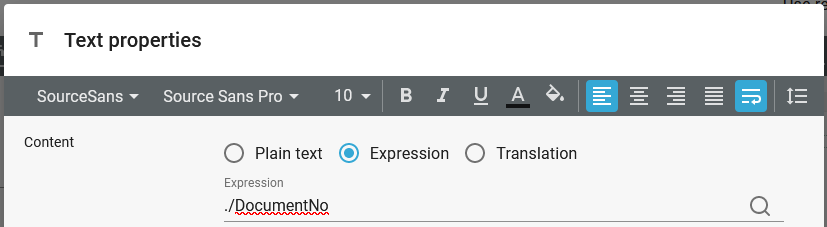
Please note, that both DocumentNo and ./DocumentNo will work in the rendered result, but the result view will also show the data of the first node, if you specify ./Document as above.
This will retrieve the values ‘1004', '1001' and '1003'.
You can also retrieve an attribute e.g. @Company.
Repeat loop for a subset of nodes
You do not need to include all the XML nodes with the same name/path in a repeat loop. You can also subset the nodes for the repeat e.g. based on attributes and/or the subtree of each of the nodes.
If we e.g. consider this XML file:
<persons>
<chairman gender="female">
<name>Maggie Frederiksen</name>
</chairman>
<person gender="female">
<name>The Little Mermaid</name>
</person>
<person gender="male">
<name>Mr. Andersson</name>
</person>
<person gender="male">
<name>Mr. Nilsson</name>
</person>
<person gender="female">
<name>Mercedes Hansen</name>
</person>
<person gender="female">
<name>Lada Jaskagidaj</name>
</person>
<person gender="N/A">
<name>Abcd Jensen</name>
</person>
</persons>
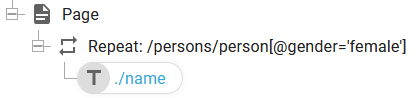
Then we can e.g. define a repeat loop, that lists the name of all female persons (a gender attribute that is female) with this repeat loop:
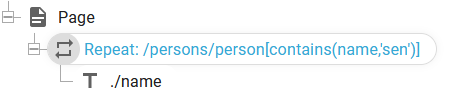
We can also condition the subset on the contents of the subset of the current node. We can e.g. list all persons that has the text 'sen' somewhere in the name node like so:
We can also condition a node set on the name of the nodes. If we e.g. have list of multiple nodes named "Adress" followed by a number (in sequence) like this:
Then we can build a repeat loop to go all of these "Adress" nodes like so:
/Root/Document/*[contains(name(),'Adress')]
If we want to print out the contents of all the Adress nodes the full setup can look like this:

Where * selects any sub-node of the Document node and the name() function returns the name of the current node. The contains function is described here.
If you want to concatenate constants with data from the XML file you can use the concat function e.g. like this:
concat('ABCD',/Data/Header/Type,'EFGH')
This inserts the XML data right in between the constants: ‘ABCDVDA4902 EFGH’.
You may notice, that there above is a blank between the XML data and the trailing constant. You can remove that by removing leading and trailing blanks of the XML data like so:
concat('ABCD',normalize-space(/Data/Header/Type),'EFGH')
You can also substring data like this: substring(/Data/Header/Type, 2,3)
The first parameter of the substring command is the string, that should be subset, the second is the start position and the third is the length, so if /Data/Header/Type contains the string ‘VDA4902', the result will be ‘DA4'.
Other string functions are:
substring-before(expression1 ,expression2)
substring-after(expression1 ,expression2)
replace(expression1, expression2, expression3)
substring-before searches for the text, expression2 inside expression1 and returns the part of expression1, that precedes the found position. This formular returns a ‘c’:
substring-before("c:\dir", ":\")
substring-after searches for the text, expression2 inside expression1 and returns the part of the expression1, that follows the found position. This returns ‘dir’:
substring-before("c:\dir", ":\")
contains returns either true or false depending on if one string is found inside of another. Examples: contains('abcdefg','de') equals true as the string 'de' is found in the string 'abcdefg'. If e.g. you want to test if one string (here a variable called $mystring) match one of the strings in a list like so: if ($mystring = 'abc' or $mystring = 'def' or $mystring = 'ghi') then ... then you can consider to do a similar test like so: contains('abc,def,ghi',$mystring).
replace replace any occurrence of expression 2 in expression1 with expression3. So the expression replace('abc@def','@','123') will result in the string: ‘abc123def’.
The function, translate is able to translate a character with another. It will search the first string for any character in the second string and if found it will use the same number in the list from the third string instead. This will e.g. replace any comma with a dot in the variable, in:
translate($in, ”,” , ”.”)
–S1– S2 S3
If the third string is empty the character will be replaced with nothing: (commas are removed)
translate($in, ”,” , ””)
You can also convert from lower case to upper case in this way:
translate($in, ”abcde” , ”ABCDE”)
If substring-before and substring-after is not able to find the text, then an empty string is returned.
If you want to insert the current date (timestamp) e.g. as a text, then you can use the xpath function, current-date() and current-dateTime() like so:
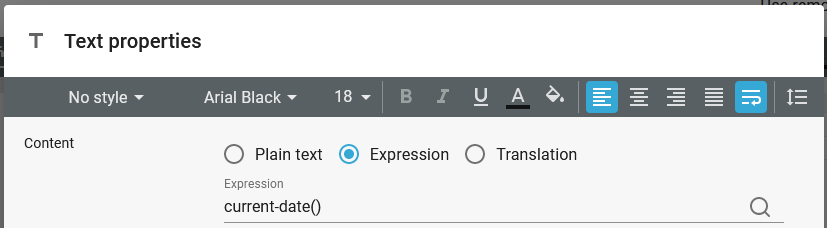
This outputs the date (and time if selected) in this format:
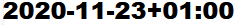
(Year, month, date, hour and timezone)
You can however reformat the date (and time) with the ng:dateTimeFormat and ng:dateFormat functions.
If you want to change the formatting or only use a part of it, you can e.g. move the result into a variable and e.g. use a part via substring.
Add or subtract a number of days, months or years
You can use the standard Xpath 2.0 function, xs:dayTimeDuration(), if you want to add or subtract a number of days to/from a valid date.
You can e.g. use this function to add 5 days to the current date with this Xpath expression: current-date() + xs:dayTimeDuration('P5D')
The format of the xs:dayTimeDuration('P5D') is:
P indicates a period indicator
5 (an integer) is the number of days to add or subtract.
D is indicates that it is a number of days.
If you want to subtract a number of days, then you can proceed the duration with a minus like so:
xs:dayTimeDuration('-P5D')
You can also add/subtract a number of years and months with the function: xs:yearMonthDuration('P1Y2M'). It follows a similar structure for the format:
P indicates a period.
1 (an integer) is the number of years to add/subtract.
Y indicates that the previous integer is a number of years.
2 (integer) is the number of months to add/subtract.
M indicates, that the previous integer is a number of months.
Example
If you have a date in a string with which you want to add or subtract a time period, then you first need to convert the date into the format: 'YYYY-MM-dd', where
YYYY is the year (4 digits), MM is the month (2 digits) and dd is the date of the month (2 digits).
If e.g. you want to add 30 days to July 4th 2025, then you need to e.g. use substring and concat to build this string: '2025-07-04'. Then you need to convert this string into a date with the function, xs:date() and then add the 30 days like so:
xs:date('2025-07-04') + xs:dayTimeDuration('P30D')
This expression returns the date: 2025-08-03.
Condition an element on the current date
One way to use the current-date() XPath function is to condition elements in the designer by comparing the current date with an interval of date. This can e.g. be used for including a christmas greeting in the designer.

The setup consists of 3 parts:
1.A definition of a variable, that we in this example name: Currentdate. In line 1 this expression is used in order to extract the current date and to format it in the format year,month and day of the month with no delimiters. If we start from the inside the function, current-date() returns the current date in the format: year-month-day of the month+timezone. This date is converted into a string with the string() function. The result of the string function is used as an argument in the substring function, which here extracts the first 10 characters from the current-date() function, which means that the reference to the timezone is removed. The ng:dateFormat function finally removes the '-' between the year, month and day (this could also have been achieved with the translate xpath function). Now the Currentdate variable contains the year month and day without any delimiters.
2.In the second line we compare the Currentdate variable with two fixed dates, so that the christmas greeting is only included in the output in the range from December 1st to December 24th.
3.Finally in the third line we print out the text 'Merry christmas' - but only i the condition above is true.
Numeric operations:
If you want to do numeric operations with numbers, that are considered a string, then you need to explicit tell XPath, that a value is numeric with the function number(). That is e.g. the case, if you want to extract data from an input spooled file and use that in a numeric calculation.
This XPath expression e.g. fails in the designer (even though positions 57-60 in line 13 in the sample spooled file is 1004):
ng:spoolMap(//page[1], 57, 60, 13, 13)+100
It fails with the error message: Cannot evaluate string+integer.
The solution is to convert the string from the spooled file into numeric like so:
number(ng:spoolMap(//page[1], 57, 60, 13, 13))+100
You can also do normal calculations as adding, subtracting, multiplicating, dividing in XPath. This can e.g. also be stated as an XPath expression:
substring(/Data/Header/Type, 4,3)*5 div 6 (you need blanks around ‘div’)
With the value (‘VDA4902') as mentioned above (for /Data/Header/Type) this will be calculated as 490 multiplied with 5 (equal 2450) divided by 6 making the result: ‘408.3333333333333'.
So as you can see divide is stated as ‘div’ and modulo is ‘mod’.
A numeric result is converted to a string when returning the value so you can e.g. combine substring functions to the result, so we can even limit the number above to 2 decimals in this manner:
concat(substring-before(substring(/Data/Header/Type, 4,3)*5 div 6,'.') ,'.',substring(substring-after(substring(/Data/Header/Type, 4,3)*5 div 6,'.'),1,2))
Numbers must be written with a dot as decimal point without any thousand separator. To convert a decimal comma into a dot and to remove any dots (used as 1000 delimiter) you can use the translate function like this: translate(string,”,.”,”.”). Assuming you are using a dot as a decimal point and a comma as thousand separator you can remove the commas with this expression: translate(string,”,”,”“).
The result can then be used in numeric expressions.
The explaination of the above is, that we concatenate the substrings consisting of:
1) The part of the amount, that is in front of the ‘.’ i.e. ‘408' in this case.
2) The ‘.’.
3) Only the 2 first characters of the part of the amount, that is after the ‘.’ i.e. ‘33' in this case.
- making the final result: ‘408.33'.
A more simple round of can also be done if you set the data type (in the text element) to numeric and then use this formula:
round(100*(/Data/Header/Type*5 div 6)) div 100
The round() function will round off to the nearest integer. round(1.234) outputs 1 and round(0.5) also outputs 1.
Please note, that Xpath is as default using round half to even, when you set a fixed number of decimals on a numeric field via a mask on either the built in function: ng:numberFormat or the standard Xpath function: format-number below.
The floor() function rounds down to the nearest integer (whole number without decimals), so e.g. floor(1.5) and floor(1.999) both outputs 1.
The ceiling() function rounds up a number to the nearest integer (whole number without decimals), so e.g. ceiling(1.1), ceiling(1.5) and ceiling(1.999) all outputs 2.
The standard format-number Xpath function has these parameters:
format-number(number ,pattern [,decimal-format] )
number
The number to format. The number must be in the correct format i.e. no thousand separator and the optional decimal point must be dot. You can use the translate() function to remove or replace specific characters.
pattern
The pattern of the number. You can use these options:
0 (Digit)
# (Digit, zero shows as absent)
. (The position of the decimal point Example: ###.##)
, (The group separator for thousands. Example: ###,###.##)
% (Displays the number as a percentage. Example: ##%)
; (Pattern separator. The first pattern will be used for positive numbers and the second for negative numbers)
decimal-format (optional)
This is not covered in this manual. Refer to standard XPath descriptions for full details.
Examples of the format-number.
The specifications on the left results in the output on the right:

Path expressions
Xpath also enables you to condition the path to an element. With this you can select a specific branch in the xml tree, which fits a certain condition. If you e.g. consider the intro_demo.xml file you can e.g. find the contact person for the company at a specific address in this manner:
/Root/Document[Adress1='Tulip Road 16']/Contact_person, which will return ‘Susan Sunflower’.
You can also refer to a node number in the tree. As this document is the second you can also find the same contact person via this expression:
/Root/Document[2]/Contact_person
You can verify, if a node contains a special text. Here we check if a node contains the text 'HELLO':
boolean(/Root/Greeting[contains(.,'HELLO')])
(The trick is, that the first paramater of contain is a dot, which refers to the current node).
.
If you want to do multiple comparisons, then you could use nested if elements or the select element, or you could use an xpath expression, that returns either true or false with and/or between each comparison.
Please notice, that if you want to test in a condition if two parameters are not equal, then you should compare with != e.g. $DocumentNo!=2 means: Test if the variable DocumentNo is not 2. You cannot not use this <> to test if two parameters are not equal.
This xpath expression will return true, if the variable is a single numeric character:
$var1>='0' and $var1<='9'
You can also use boolean expressions to check if e.g. a string is equal to any of the strings in a list. The ‘string’ do not even need to be a string, so this xpath comparison could be used:
$var1=(0,1,2,3,4,5,6,7,8,9,'a','b','c','d','e','f',’A’,’B’,’C’,’D’,E’,’F’)
This returns true, if the variable, var1 contains a single hex character, which could be a character in the ranges 0-9, a-f, or A-F.
In XPath you cannot only use a boolean expression like above, but you can also use an if..then..else condition to decide what value the XPath expression should return based on a comparison. An example of an if..then..else:

The example above can be used in a workflow, that is to print something. The input XML file may or may not include a number of copies in the node /Data/Header/Copies. The expression above does this: If this node is not empty ("!=" is the same as "not equal") then use the number found in this node, but if it is empty, then use the value 1 instead. You need of course a text delimiter like '' or "" around a string, if the expression is not to return a number.
You can even use regular expressions with Xpath, if you use the matches Xpath function. This expression checks the variable, MyVariable:
matches($MyVariable, "^(DIN|ISO) A[3-5]$")
The regular expression above tests, if the variable:
•starts with either 'DIN' or 'ISO'
•then a space and the letter 'A'
•finish with 3, 4 or 5
You can use the expression in IF- and select elements to let the output depend on the result of a test.
Remember, that you can combine the XPath functions, and that there are many other functions not mentioned here. This appendix hopefully gives you an idea of how strong a tool this is. You can e.g. refer to this link for additional information: http://www.w3schools.com/xpath/xpath_functions.asp
Apart from the normal Xpath (2.0) functions variables can also be used.
If you want to output the sum of all detail lines of a document, then the best solution is to output a sum, that is included in the input file, but if that sum is not included, then you can either create a repeat loop in the designer and sum up the values in a variable, but you can also simply use the Xpath sum function like to:
sum(/Root/DetailLine/Amount)
If you want to know how many nodes there are in an input XML file, then you can use the XPath function, count. The count function simply counts the number of nodes with the specified path. This function counts the number of detail lines in an XML file: count(/Root/Document/DetailLine)
How to use attributes of a node
If you consider this sample XML file:
<persons>
<chairman gender="female">
<name>Maggie Frederiksen</name>
</chairman>
<person gender="female">
<name>The Little Mermaid</name>
</person>
<person gender="male">
<name>Mr. Andersson</name>
</person>
<person gender="male">
<name>Mr. Nilsson</name>
</person>
<person gender="female">
<name>Mercedes Hansen</name>
</person>
<person gender="female">
<name>Lada Jaskagidaj</name>
</person>
<person gender="N/A">
<name>Abcd Jensen</name>
</person>
</persons>
Here the gender is defined as an attribute of the chairman and person nodes.
In the designer the attributes in XML files are shown with a preceding @-sign as below:
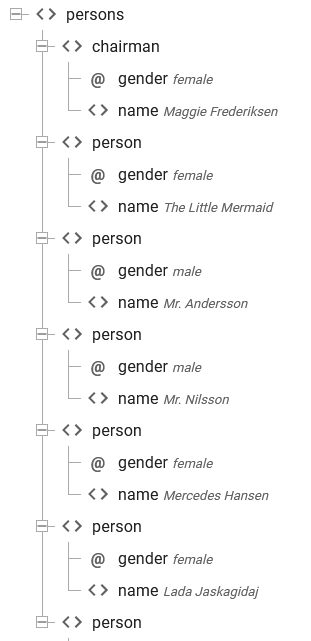
If you want to refer to the gender of the chairman, then you can in the designer simply drag the attribute to the result to map it.
The Text element will look like this:
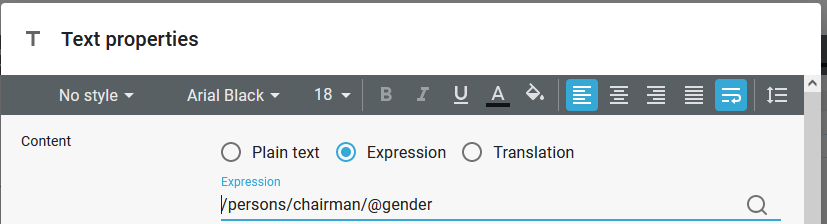
If you want to count all the male persons, then you can that like this:
count(/persons/person[@gender='male'])
How to ignore namespaces in XPath
When you refer to the contents of the input XML file, then you will as default always include the namespace in the reference like e.g.
/Root/nmspc:myNode
Where nmspc is the name of the namespace.
If you want to make this work no matter what the namespace is called, then you can replace the namespace with an asterix like so:
/Root/*:myNode
You can use a local-name notation, if there are multiple namespaces with the same node:
/Root/*[local-name() = 'myNode']
How to group nodes and summarize values
This section shows how you can group nodes in an XML file e.g. to only display the unique values/groups and e.g. summarize values from each group.
For this example we can use an XML file, that looks like this:

In the XML file above there are multiple Documents (in the Document nodes) and each document can contain multiple DetailLine nodes. The DetailLine nodes are the onces, that we want to list in this section.
Each DetailLine contains a node called Product and a node called Model.
For one of the documents we find these valus in the DetailLine:

But now we only to list each unique product once and then sum up all of the models for this unique product. So we want to list Swiftview(50) and InterExcel400 once, but also only include InterForm400 once with the models summed up (515+810+890+520+530+270).
So how can we do that?
For that there are two solutions:
1.Preceding-sibling. We can do a repeat of all detail lines and use XPath functions, preceding-sibling or following-subling to count the number of nodes before or after the current node (with the same unique selection).
2.Distinct-values. We can use the Xpath function, distinct-values to generate a list of all unique values, count this number and iterate across each of these unique values.
Preceding-sibling
One way is to iterate across of all of the detail lines (of the current document) and then only list the detail line, if this is the first detail line, that contains the current product name.
This can be done with the template below:
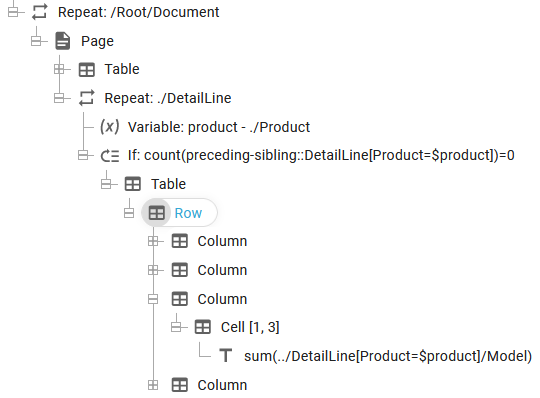
The setup is described below - line for line:
1.Go through each of the Document nodes in the XML file with a repeat.
2.We insert a new page for each document.
3.A table is inserted with the headers for the table (this should/could be inserted in a page header to handle page overflows).
4.A repeat loop iterates through the DetailLine nodes of the current document.
5.We copy the value of the product of the current DetailLine into a variable, product (case sensitive).
6.We calculate the number of preceding-siblings (DetailLines prior to the current one), that has the same product name as the current one. If there are no earlier ones (i.e. the number is 0), then we know, that this is the first occurrence of a unique product and then we want to output the current detail line. In this test we use the product variable from above ($product).
7.We insert a table to output the values of the current detail line.
8.Inside the table we print out the sum of all of the Model nodes for the detail lines, that has the same product name as the current one.
The expression: count(preceding-sibling::DetailLine[Product=$product])=0 tests the number of previous detail nodes with the same product name, but we could also use this expression instead:
count(following-sibling::DetailLine[Product=$product])=0
This expression tests, if the current node is the last (instead of the first) detail line with the specific product name.
The result of the setup above (with preceding-sibling) looks like this:

If you use following-sibling the result looks like below:

Distinct-values
If you prefer to use the Xpath function, distinct-values, then then solution can look like below:
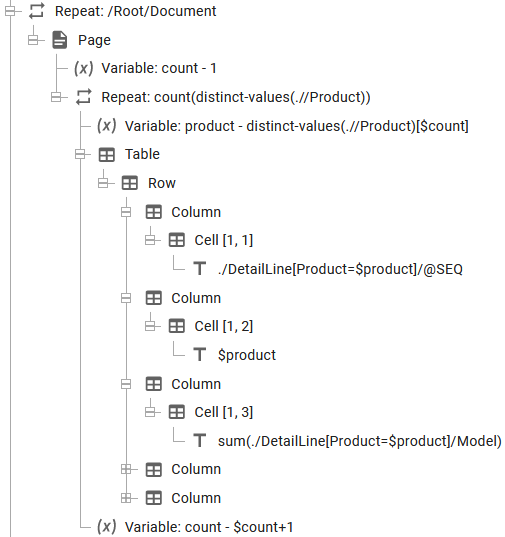
The setup is described below - line for line:
1.Go through each of the Document nodes in the XML file with a repeat.
2.Set the variable, count to 1 to start a new document. We use this variable to keep track of the current index of the distinct values.
3.The repeat loop iterates for the number of distinct-value of the product. The distinct-values returns a list of distinct (unique) values and the count function is used for counting how many unique values, that we have found. So if e.g. 4 unique values are found, then the repeat loop will run 4 times.
4.Next we update a variable, product to the product name of the current distinct value, that we intend to print out.
5.Then we insert the table that is to contain the output values.
6.In cell one we want to output the value of the @SEQ node, that has the same product name, as the one we are currently working with. We select that by comparing the value of the product inside the DetailLines with the currently selected Product name, which is stored in the variable called product.
7.In the column, where we want to print out the product we simply use the variable.
8.In the column, that should print out the sum of all Models we select a node set of all Models found in DetailLine nodes, that has a product that equals the currently selected product.
9.In the bottom we increase the counter for each iteration, when we go through each distinct value.
List values of nodes, that has a name starting with a specific text
It is possible to list the all nodes, that has a name starting with a specific text. An example of a relevant XML file can be this:
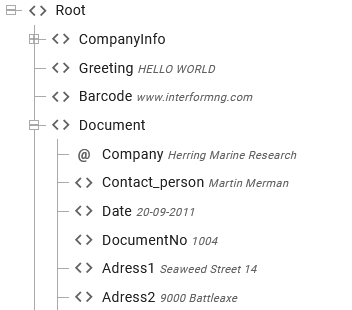
In this example we want to list the values of all the nodes, that starts with Adress and we do not know how many there can be.
A way to do that is to use a repeat loop with this specification:
/Root/Document/*[starts-with(name(),'Adress')]
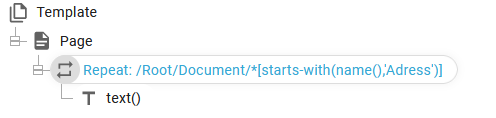
In the example above the repeat loop goes through all nodes with the path/name: /Root/Document/Adress* and with the text() specification we print out the value of each node.
In this example the output is:

Refer to nodes via the index
You can refer to a node via the index if you e.g. have multiple nodes with the same in the input XML file.
If we e.g. consider an input file with multiple detail lines like below:
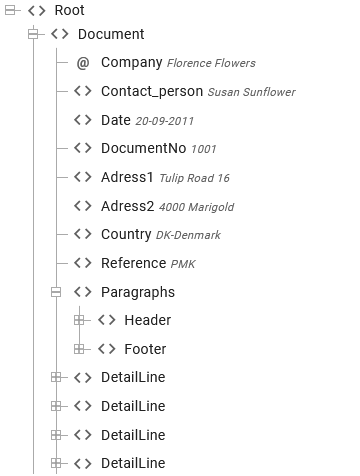
Then you can refer to a specific DetailLine node in e.g. a text element via the index like so:
/Root/Document/DetailLine[4], where this refers to the 4.th DetailLine node within the Document node.
Instead of the normal repeat like so:
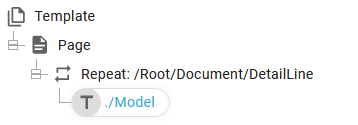
Then you can even combine variables and index like so:
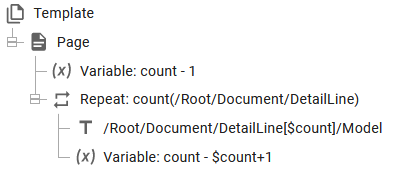
Here we first find the total number of DetailLine nodes and repeat the sub-section this number of times and keep track of the current index number via the variable, count.
Both of these repeat loops creates the same output, so as you can see you can even use an xpath expression to set the index number. A related example is found below.
Select a range of nodes via the index/position()
There is in Xpath a function called position(). This function returns the current position (index or node number). This can e.g. be used, if you want to limit the number of nodes, that a repeat is to handle.
You can e.g. consider this in the designer, if you have loaded a sample file, that contains too many detail lines which can slow down the designer.
You can limit a repeat to a range of indexes (positions) like below. If you imagine this setup, which iterates across all detail lines:
Then you can change the repeat to only process Detail lines from 2 to 4 in this manner:
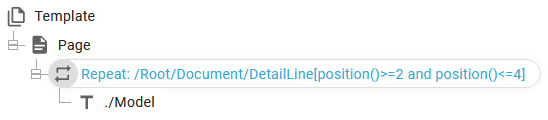
Inside the sharp brakets [] you can insert a condition that is tested for each of the detail line nodes. This can of course also be combined with other conditions with and/or.
Verify if a node exists
If you want to verify, if a node is empty, then you can use this comparison: (MyNode=''), but this only returns true, if the node, MyNode actually exists and is empty. If you use the same comparison for a node, that does not exist, then this comparison is false (unlike in InterFormNG1, which use XPath version 1). For comparisons like that there is a recommendation below.
So if you want to insert a condition, that can verify if the node exists, then you need to use another condition. One condition could be this: count(MyNode)>0 or the condition: boolean(MyNode)
In regards to performance the test boolean(MyNode) is faster, but perhaps not that clear for a new user.
So if you in InterFormNG2 wants to insert a condition to verify if the node, MyNode is either blank (null) or does not exist, then you could use this condition to combine them:
MyNode='' or boolean(MyNode)=false() or MyNode='' or not (boolean(MyNode))
An alternative is to consider the ng:compare function.
If you want to verify, if a node is not blank, then you might consider to use the comparision: MyNode!=''. This condition is however true in two scenarios: If the node, MyNode exists and the contents of the node is not empty/null, but this is expression is also true, if the node, MyNode does not exist. So if you want to verify, that there is data in the node, then you need to change the condition.
The most simple way is to do a string compare i.e. convert the contents of the node into a string and then compare the result. In this way you could substitute the condition MyNode!='' with the condition string(MyNode)!=''. This works by converting the node selection (which can be no nodes, one node or multiple nodes) into a string and the compare the string with an empty string. Please note, that the string function is a standard XPath function, that must be written in lower case.
Other solutions could be to use two tests to verify, that the node actually exists and also that the value of the node is not empty/null. You can do that with this condition:
Mynode!='' and boolean(MyNode)
another expression to do the same is:
Mynode!='' and count(MyNode)>0
An alternative is to consider the ng:compare function.
If you want to verify, if a node is blank, then you might use the comparision: MyNode=''. This condition is however false in two scenarios: If the node, MyNode exists and the contents of the node is not empty/null, but this is expression is also false, if the node, MyNode does not exist.
The most simple way is to do a string compare i.e. convert the contents of the node into a string and then compare the result. In this way you could substitute the condition MyNode!='' with the condition string(MyNode)=''. This works by converting the node selection (which can be no nodes, one node or multiple nodes) into a string and the compare the string with an empty string. Please note, that the string function is a standard XPath function, that must be written in lower case.
Other alternatives are here:
If you really want to test, if the node does not contains data, then you should use a condition like this: MyNode='' or not(boolean(MyNode)) or
Mynode='' or count(MyNode)=0
You can refer to examples in the sections above: Verify if a node exists and Verify if a node is not blank for other examples how to test on the contents of a node, while being able to handle non-existing nodes. An alternative is to consider the ng:compare function.
Introduction to the boolean() function
The boolean function returns a boolean i.e. either true() or false() depending on the argument. In InterFormNG2 it can e.g. be used for verifying if a nodeset is empty e.g. before using the same nodeset in a Repeat element.
If the nodeset /abc/node is empty, then this expression returns false():
boolean(/abc/node)
and true() if the nodeset exists.
An example of where is useful is included below in the section Avoid warnings in the job logs for repeats, that selects no nodes.
Add preceding or trailing zeroes/blanks
If you have a string of a variable length and you want to fill out with leading or trailing blanks or zeroes to a specified length, then you can do that as below. In the examples we refer to the string with the variable length as $input:
Add leading/preceding blanks up to the length of 10:
substring(concat(' ',$input),string-length($input) + 1,10)
Add leading/preceding zeroes up to the length of 10:
substring(concat('0000000000',$input),string-length($input) + 1,10)
If the $input variable is numeric, then you can also use the more simple function:
ng:numberFormat($input,'us','0000000000')
Add trailing blanks up to the length of 10:
concat(substring(concat($input,' '),1,10)
Add trailing zeroes up to the length of 10:
concat(substring(concat($input,'0000000000'),1,10)
If the $input variable is not a string, then you can use the function, string to cast it as as string e.g. like below:
substring(concat('0000000000',string($input)),string-length(string($input)) + 1,10)
Avoid warnings in the job logs for repeats, that selects no nodes.
In the job logs you might see this warning:
Template.001014: Invalid element [idxx] 'Repeat' expression evaluated to 0 nodes:

If you want to avoid such warnings, then you can consider to add a condition to test if there are any nodes for the repeat like below:
Change this:
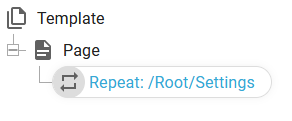
And add a condition either like this:

The boolean() function returns true() if there is at least one node with that path. This is the most efficient test.
The alternative (less efficient way) is to count the number of nodes and compare that with zero like below:
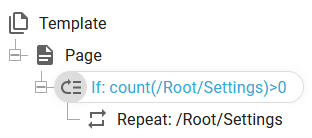
Identify the current node/line number within a repeat e.g. in a transformation
In a transformation you cannot use a variable to keep track of the current node number, so if you e.g. within a repeat wants to calculate the current node number, then you can consider this expression:
count(preceding-sibling::*) + 1
This is e.g. relevant in a transformation, where you cannot use a variable to keep track of this node number - especially if you want to verify the current line node number in a repeat for the line nodes of a spooled file.
Tokenize: Convert a string into a list and use index for references to this list
If you have a string, that contains a list of elements and you would like to refer to these elements by an index, then you should consider the standard tokenize xpath funtion.
The tokenize function can be used in the way, that you can convert it into a list, which is defined by a delimiter e.g. to extract each word from a sentense.
For this example we can consider this variable:
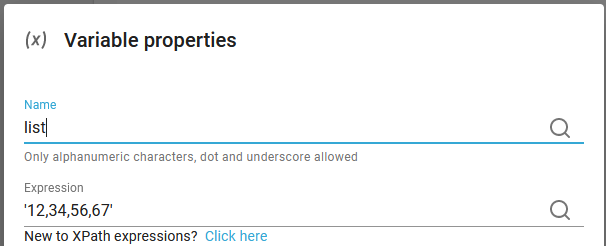
We want to convert this into a list of 4 elements while using comma (,) as the delimiter between each element.
That can be done in this way:
tokenize($list,',')
So the first parameter of the tokenize is the input string, that we want to convert into a list and the second parameter is the delimiter.
Now we can use a normal index to extract a specific element from the list like below:
This expression returns '34' as this is the second element:
tokenize($list,',')[2]
We can also choose to print out all elements in the list like below:

This results of course in this list:

You can also use tokensize to extract each word from a string like below.
If the variable list is defined like so:
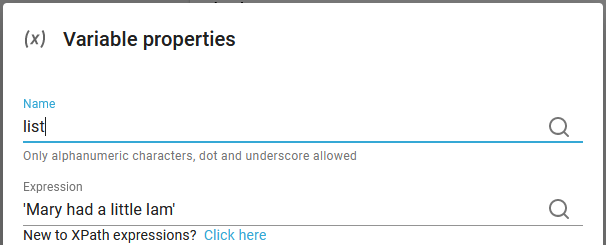
Then we might want to extract a specific word (where the words are delimited by a normal space).
In this case we use a space as the delimited as below:
This extracts the second word (which is 'had'):
tokenize($list,' ')[2]
This repeat outputs each word on separate output lines:

Error: Unsuitable types for + operation (xs:string, xs:integer)
You might see the error above in a job log when you try to add a value to a variable. The reason for this error is, that the workflow variables are all handled as strings and it is not possible to add a numeric value to a string, so you will see the error above if you e.g. try to execute a workflow component like below:
INCORRECT:

The expression above is not valid in a workflow. Instead you first need to convert the value of the variable into a number before the addition - like below.
CORRECT:

Connect preceding or following node sets to the main node set
In this example we will see how it is possible to connect detail node sets, that are found directly before or after the main nodeset and present them in a connected way in the output.
As an example we consider an XML file with a structure like below:

For each of the Document nodes there may be a Header and a Footer section. Both of them are optional, but the Header is always found just before the Document and the Footer is always found just after the Document.
It is possible to link the Header/Footer lines with the main Document node in a template like below:
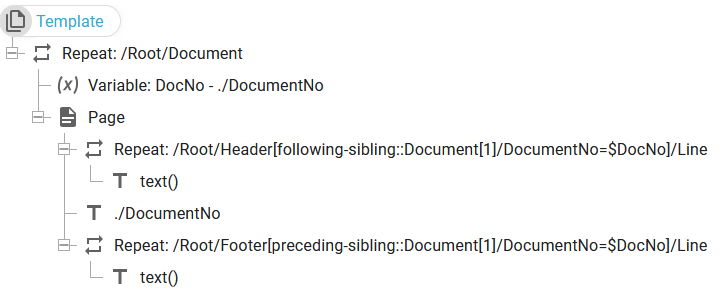
In the setup above we create one separate page for each Document node and inside the page we select the Header lines with this repeat:
/Root/Header[following-sibling::Document[1]/DocumentNo=$DocNo]/Line
Previously the variable, DocNo is set to the current DocumentNo value, and the repeat selects the Header Line nodes for which the following sibling (to the Header node) contains the same value for DocumentNo as the current DocNo. In the repeat expression Document[1] is specified. In that way it verifies that the first of the following Document contains the matching value.
The same principle is used for the footer: Here we compare with the first of the preceding Document nodes.
The output is 3 pages like below:


