InterFormNG2 can with the M3 module be setup to process files directly from InterFormNG2. This is covered in the section, Infor M3 integration.
After both Infor M3 and InterFormNG2 has been configured, the next thing is to setup InterFormNG2 to process the files from M3.
For that you should consider the workflow input type, M3 input. This input type has these parameters:
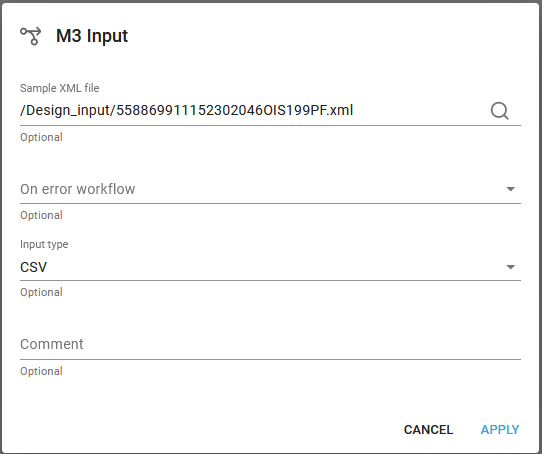
The M3 input type has these parameters:
Sample XML file
An optional sample XML file from the documents Library. This can e.g. be an input file from Infor M3, that you at some point have converted into an XML file. It can be a good idea to load a load a sample file, if you intend to use the contents of the input file in the workflow.
On error workflow
An optional workflow to call, if an error should occur during processing of an input file.
Input type
The type of file, that the workflow expects to receive. You can in a workflow only insert components, that can process the files with the type of the current payload.
Some, older M3 versions (e.g. version 10.2) produce text files. If you setup the workflow to process the text files as if they are CSV, then you can e.g. use the CVT to XML component to convert the input text file into an XML, which makes it easier to extract information from the input file.
If you are using such an older version of M3, then you should consider to use this component as the first one with these parameters:
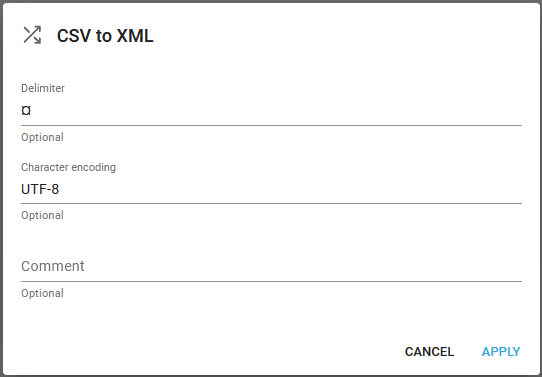
For the next component you can e.g. extract information from the XML file e.g. the printer file with the component, Set one workflow variable:
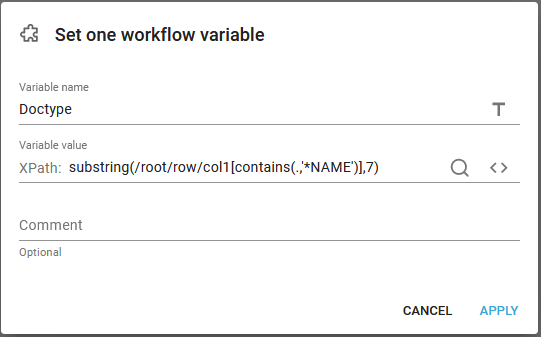
With this we can extract the printer name e.g. OIS199PF from the input file and use that e.g. for the template name and other.
The header of the M3 file looks like this:
*SERVER 192.168.123.123
*PORT 20202
*NAME OIS199PF
With the function, substring(/root/row/col1[contains(.,'*NAME')],7) we extract the text from position 7 (to the end of the current line) of the line/node where *NAME is found.
Before you process the M3 file further you should consider to transform the XML file into a better format with an xslt transformation.